关于经典面试问题延迟双删
摘要
互联网后端开发的岗位面试中,“如何保证数据库和缓存的数据一致性”是非常高频的问题,网上存在两类主流方案,分别是1. 延迟双删;2. Changed Data Capture(CDC)方案。其中延迟双删方案几乎成为了该面试题的标准答案。本文通过分析延迟双删存在的问题,说明为什么不推荐使用延迟双删方案,并提出一种更简单的、基于乐观锁的替代方案。
延迟双删的动机
我们来把场景描述清楚:数据库通常是MySQL,缓存通常是Redis,引入缓存的目的是靠缓存来处理大量的读流量,减少对数据库的访问。系统的负载具有对单个key的较高的并发读写流量。我们的设计目标是,对于单个key来说,使得缓存和数据库的数据尽可能地保持一致。
直观的缓存更新方法,无非是在
- 先更新数据库再删除缓存
- 先删除缓存再更新数据库
- 先更新数据库再直接更新缓存
- 先直接更新缓存再更新数据库
之间选择。然而,以上无论是那种方案,都存在一些边界case导致数据库和缓存长时间的不一致。详细的分析可以参考网上的各类文章,这里就不再赘述。这里我们需要回忆的是,在这几种方案里,先更新数据库再删除缓存的方式是相对来说更好的。
延迟双删则是在先更新数据库再删除缓存的方案上,再补充了一个延迟删除缓存的操作,从而一定程度上解决并发流量将旧数据写回了缓存的问题。
延迟双删的问题
首先我们需要承认,不管用什么方案,数据库和缓存必然存在一定时间内的不一致,否则分布式共识算法就没有诞生的意义了。所以我们追求的是一种方案,能够尽可能减小数据库和缓存数据不一致的这个时间差,达成最终一致性。
延迟双删的精髓在于“双删”,即通过延迟的第二次删除缓存,依赖后续的读请求将新数据写回缓存,以解决第一次删除缓存后其他的并发线程将旧数据写回了缓存从而导致的不一致问题。但是我们回过头来看,延迟双删方案为了解决数据库和缓存的不一致问题,引入了什么弊端。
- 首先,第二次的删除导致服务必须再次从数据库中读取,增加了数据库的访问,从而引发更多的读延迟;
- 其次,延迟的时间如何抉择?延迟时间太小,则延迟双删没有解决问题;延迟时间太大,则又会导致缓存不一致的时间太长。对于不同的数据、业务的高峰期和低峰期,是否需要不同的延迟时间?这个时间是否需要动态调整和测试确定?
- 然后还有如何实现延迟删除,是直接在内存中异步延迟,还是通过定时任务和消息队列来实现?
这些问题都是我们在落地延迟双删方案时需要考虑的。其中第一个问题,和普通的先更新数据库再删除缓存相比,延迟双删多引入了一次对数据库的访问,这和我们引入缓存的目的相背;第二个问题,采用动态调整延迟时间需要引入额外的算法,在工程中这不太现实。因此通常情况下是直接拍一个时间,比方说1秒钟,并且我们需要注意的是,即使有了这个延迟的删除,依然不能够根除数据不一致的问题,仅仅是降低了概率。从设计的角度来看,当我们需要拍脑袋决定一个数值的时候,我们就该怀疑方案设计的方向是不是有问题了(个人观点,不太喜欢这种靠天吃饭的方案);第三个问题,引入定时任务和消息队列的方案太重了,内存中直接延时删除尚且可以接受,但依然引入了很多复杂性,例如部署变更导致服务在延迟时间到达之前重启等。
一致性模型回顾
假设这几个问题,我们已经有了心理准备,那么延迟双删是否就没有其他问题了呢?其实不是,在讨论具体的问题之前,让我们先回顾下分布式系统中的一致性模型:
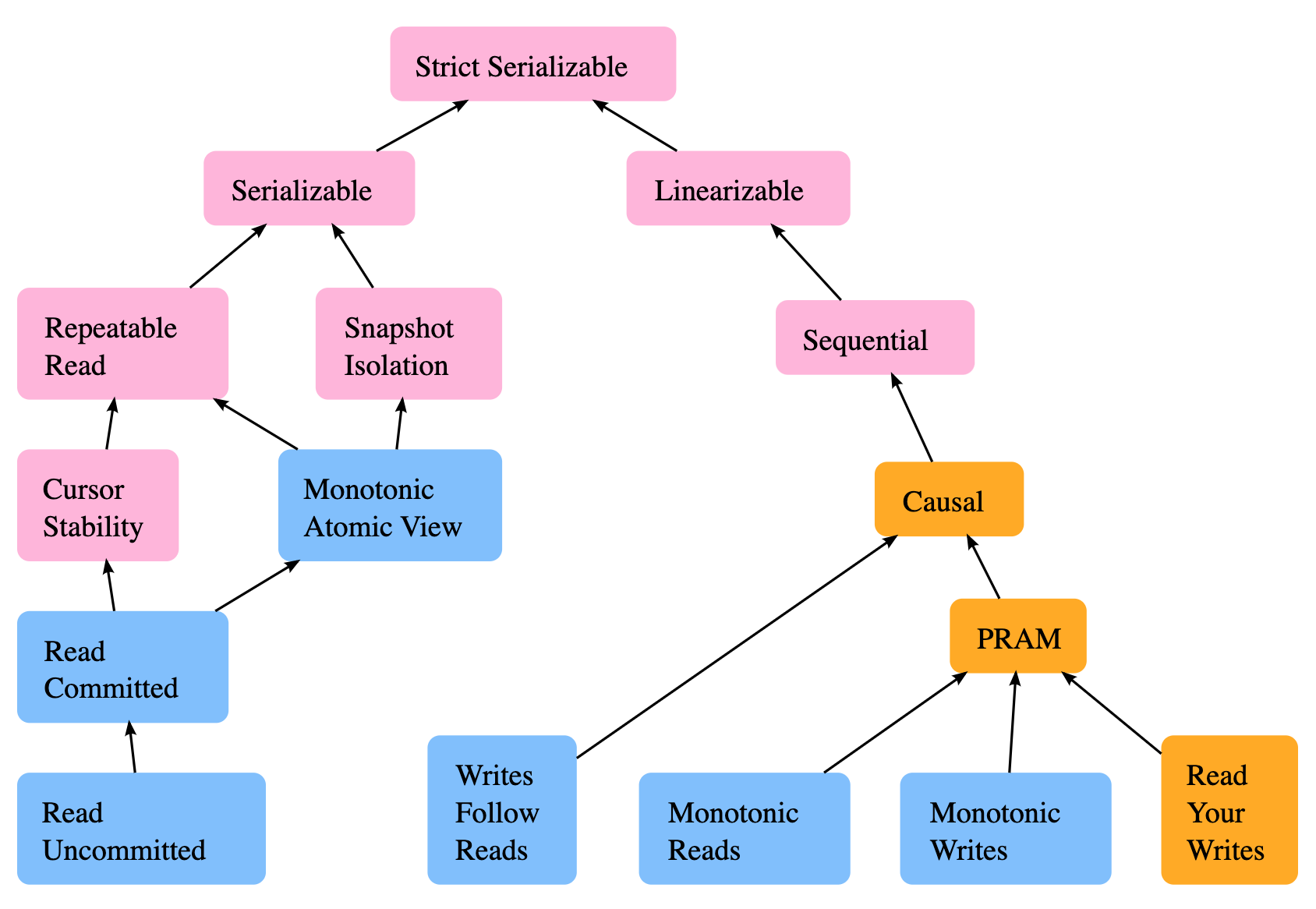
如上图所示,左边是和数据库事务相关的模型,在我们的场景中主要关注的是单个key的一致性问题,因此我们关注右半部分,尤其是Sequential(次序一致性)、Causal(因果一致性)以及Monotonic Reads(单调读)。这三种一致性模型的具体含义这里就不赘述,感兴趣的可以阅读链接中的描述。
延迟双删不满足单调读一致性
回到延迟双删问题,考虑下面的边界情况:
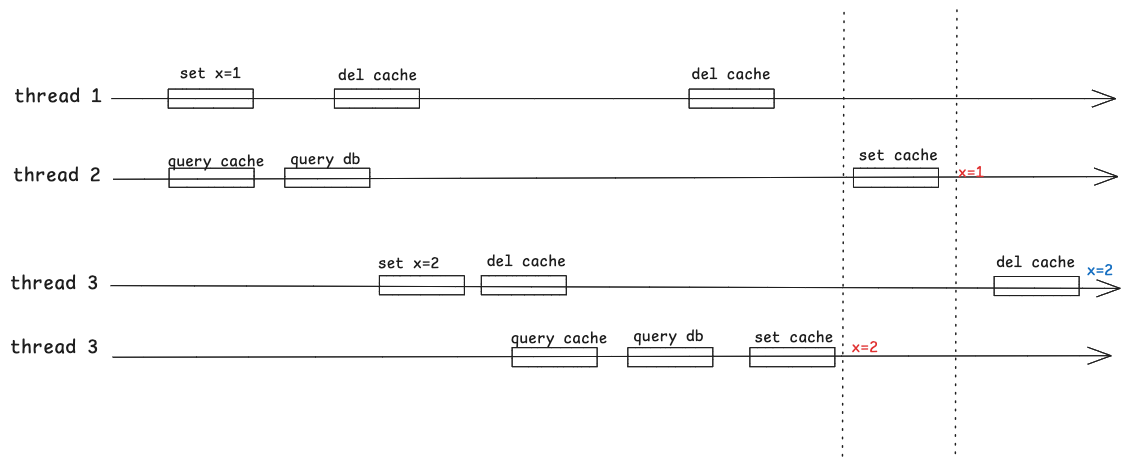
如果所示,四个线程分别进行自己的读或者写的逻辑,其中
- thread 1首先将x设置成1,然后删除缓存;
- 此时thread 2查询缓存没有命中,然后查数据库得到x=1,准备将x=1写回缓存,假设此时thread 2所在的进程因为网络抖动或者是长GC等原因,写回的操作稍微延后了一些;
- 在thread 2查完数据库之后,thread 3将数据库中的x设置为了2,然后删除缓存;
- 此时thread 3查询数据库得到x=2,然后非常顺利地将其写回了缓存,此时缓存中x=2;
- thread 2苏醒,并继续将x=1设置到缓存,此时缓存中的x=1;
- 如果延迟时间设置的足够好的话,thread 3的第二次删除,导致更新的x=2最终被写回了缓存,此时缓存和数据库实现了一致。
在我们构造的这个例子中,缓存中的x首先是被设置成了2,然后被设置成了1,最后再次被设置成了2,因此存在一些用户可能在先读到x=2之后又读到了x=1,很快又读到x=2。尽管最后我们将缓存更新成了正确的值,但是这种现象破坏了单调读,因此也就破坏了因果一致性。不过好在大多数情况下,我们允许的并发更新之间本质上就没有所谓的因果关系,因此这样的现象,一些业务场景尚且可以接受,顶多影响用户的体验。
但是我们知道了,延迟双删除了因延迟时间的设置导致的缓存里存入旧值问题,还可能存在这样的因果关系问题,在一些业务中可能是不可以接受的。更坏的是,问题还没有结束。在我们的例子中,假设还有源源不断的并发的读写,而本质上读和写的这些缓存写回、缓存删除等操作的先后顺序在一定程度上可以随便排序,实际上在持续的高并发的写和读的过程中,缓存和数据库也许大部分时间都是不一致的。只有等到写的流量稍微降下来之后,才能达到最终的一致性,这与问题的假设的场景又相背;而如果业务是持续有大量的并发写入,引入缓存的必要性就存疑。
替换方案
为了实现延迟双删,我们需要引入异步逻辑,消息队列和定时任务的方案显得过于重,而即使是服务直接做内存中的延迟,也会使得系统变得极其复杂,难以追溯和排查。尽管如此,我们实现的系统依旧存在上述分析的不一致问问题。那么问题究竟在哪儿?
从我个人的思考来看,这其实不是一个技术问题,而是一个权衡取舍问题。首先,缓存的引入是为了应对读多写少的负载,大量的读请求可以享受缓存带来的高性能。前面也提到了,在不引入分布式共识算法(或更加复杂的分布式事务)的前提下,缓存一定存在和数据库不一致的时间区间,所以我们既想要缓存带来的高性能,有想要数据的一致性,本质上就是既要又要,这很难做到。而延迟双删本身的不优雅,其实也是一种设计不合理的暗示。
用高写性能的数据库替换MySQL
所以如果我们的业务场景就是写多读少的话,我们其实可以考虑去掉缓存,并将数据库从经典的MySQL换成写性能很强的数据库,比方说基于LSM-Tree的数据库系统,例如HBase等,甚至是半内存数据库,例如OceanBase等。当然,这通常意味着需要自运维或者花钱买服务,对于很多的业务来说是难以接受的。
CDC方案
换不了数据库,那有没有替代的方案呢?前面提到了CDC的方案,常见的就是用binlog的监听工具,这样就大大简化了缓存更新逻辑的设计,只需要消费binlog更新数据库即可。剩下需要考虑的就是延迟问题了。CDC方案使用得当的话,我们可以实现次序一致性。
基于内存聚合的方案
此外,我想到一种类似于Calvin的分布式事务方案,该方案在内存中聚合10ms内的事务,并进行排序,另辟蹊径地解决了分布式协调问题,从而不需要做两阶段的提交。
回顾我们的场景,如果有单key的大量并发写,我们是否可以考虑在内存中聚合一定时间区间的(例如10ms)的并发写请求,考虑到这些写请求并没有因果关系,我们只取其中一个写请求作为这个时间区间内的“获胜者”,再去更新数据库;同时,要更新缓存时,我们依旧可以在单机内聚合相同时间区间的写流量,通过对比version(参考下一节),取最高version的数据作为该时间区间内的“获胜者”,用于更新缓存。需要注意的是,这个方案需要结合业务来决定,并发更新如果失败,对于调用方来说会不会影响后续的其他操作,是否需要独立的状态码区别等,这里仅仅抛砖引玉。
基于乐观锁的方案
其实还有一种常常被忽略的方案,就是基于乐观锁和用Lua脚本更新Redis的轻量级方案,下一节详细描述一下这个方案。
这个方案很简单,我们引入一个单调递增的version属性,用于记录数据的更新版本,从而认为地将数据全序化(即使得任意的两个并发更新都可以比较先后顺序)。首先在MySQL的表结构中新增version字段,例如:
CREATE TABLE table_name(
id BIGINT AUTO_INCREMENT,
val VARCHAR(100) NOT NULL DEFAULT '',
version INT NOT NULL DEFUALT 0,
PRIMARY KEY(id)
) 这里省略了其他属性。当然,通常数据表里都会有更新时间字段,我们可以把更新时间作为版本,只要是能够自增的就可以(如果要用于并发处理的话,我们需要将其设置为毫秒级,秒级是不够的;此外,我没有研究过如果数据库server所在的机器出现了时钟回拨,是否会影响到数据库的时间赋值):
updated_at DATETIME(3) NOT NULL
DEFAULT CURRENT_TIMESTAMP(3)
ON UPDATE CURRENT_TIMESTAMP(3)这里我们还是以逻辑version为例。更新的流程简化如下:
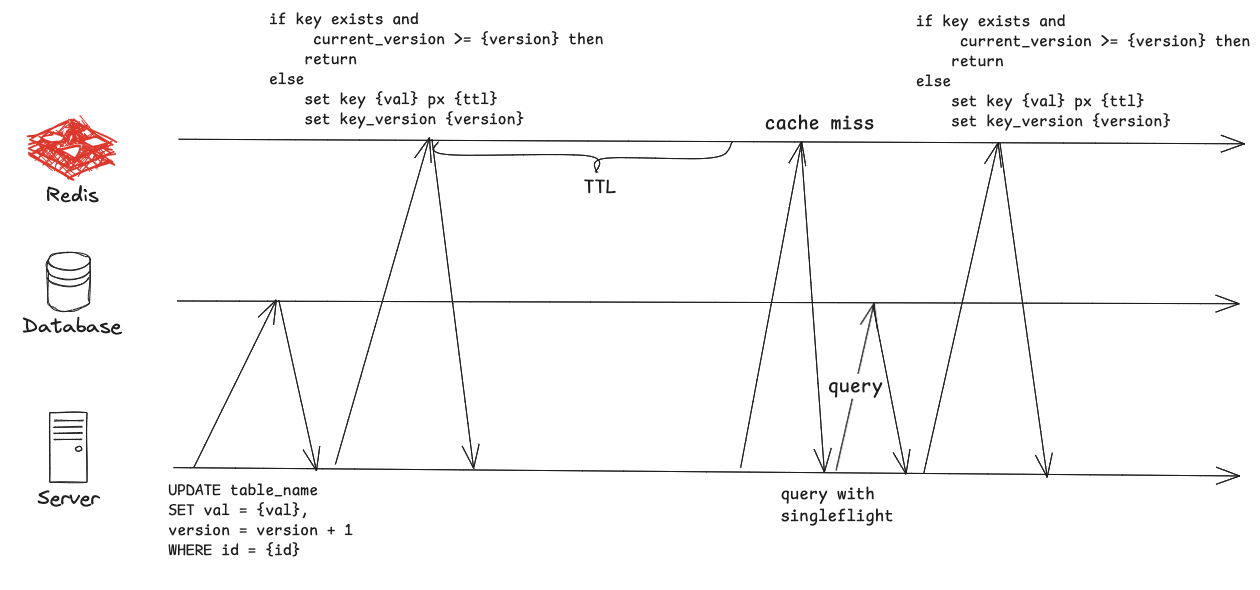
如果所示,每次更新数据库中的数据的时候,我们将数据中的version自增1,实际上,我们可以将更新放在一个事务里,从而获取最新的版本值,例如
var version int32
Transaction(func () error {
result, err := db.Exec("SELECT * FROM table_name WHERE id = ? FOR UPDATE", id)
if err != nil {
return err
}
version = result.Version + 1
_, err := db.Exec("UPDATE table_name SET val = ?, version = version + 1 WHERE id = ?", id)
if err != nil {
return err
}
})
// then update cache with versionLua脚本如图中的伪代码所示,当key不存在或者当前key在缓存中的version小于参数中的version时,我们才更新缓存中的值和version,否则忽略更新缓存。当然,数据本身和version可以用不同的Redis key,通过hash tag使其在一个slot里,也可以仅用一个Redis key,采用hash结构存储value和version。
在这两个步骤之后,无论有多少的并发更新,写入Redis的永远是最新的数据,由此可见,该方案实现了次序一致性,要强于延迟双删提供的一致性级别。
一些优化点
首先是异常处理,如果DB更新成功,但是Redis更新因为网络问题失败了会怎样?如果不是最高version的请求失败,则无关紧要,只要最高version的更新成功即可。如果是最高的version的请求失败了,并且在接下来的一段时间内都没有更新的update操作,则缓存会在TTL内不一致,等缓存过期后,新的读取请求将最新版本的数据写入Redis。因此,缓存的TTL不建议设置的过大,防止长时间的数据不一致。
这个问题也有优化的办法,我们可以增加一个步骤,那就是读流量读取缓存数据的时候,同时将TTL拿到(设置缓存时直接将TTL附在key上或者用pipeline获取),若距离TTL还有一段时间,例如还有2/3的TTL,我们可以随机性地发起一个请求去数据库里查询一次是否有更高version的数据,如果有,则异步更新写回缓存。这个操作可以加分布式锁,使得全局只有一个请求访问数据库。不过,在有足够并发更新的情况下,我个人认为这个优化不是很有必要。
还剩一个问题是,缓存过期后如何处理缓存击穿问题,这里我的方案是采用Golang中的singleflight方案(Java语言中也有开源类似功能的轮子),即同一台服务器上同一时间只允许一个数据库请求发出,其他的请求在内存中等待即可。
此外,我们还可以将脚本直接存储在Redis中,通过sha来调用,减少每次parse脚本的性能损耗(必要性可能也不大)。
总结
总结一下就是,延迟双删是一个过于复杂且依然没有解决问题的方案,他的使用场景应该是:并发写流量不是特别大,并且不同的写请求没有因果关系,
基于乐观锁的方案,逻辑简单清晰,且无需考虑大量的边界case,是一个值得考虑的方案。我目前想到的不足是,可能需要建表之初就采用该方案,否则临时增加字段,可能需要更多的考虑。
cache — May 3, 2025